

AI Chatbot ทำง่าย ใครๆก็ทำได้ — แต่ที่พ่นมา มันจริงหรือหลอก?
AI Chatbot ทำง่าย ใครๆก็ทำได้! ขอแค่คุณต่อ API เป็นก็พ่นได้แล้ว 🙂
แต่! สิ่งที่พ่นมา มันจริงหรือหลอก? ทำไมไม่มีใครบอกกัน
ปัญหาที่ไม่มีใครพูดถึง
ผมเจอบทความนึงเกี่ยวกับ HR ในสาย Tech ที่กำลังหา AI Engineer สาย LLM เขาบอกว่า:
“ส่วนใหญ่ที่เจอก็จะเอาของสำเร็จรูปมา Plug กันเป็น — และใช่ครับ ผมก็ทำแบบนั้น 😅”
สิ่งที่ตลาดหาจริงๆ ไม่ใช่คนที่เอา AI มาใช้เป็น แต่คือ คนที่เข้าใจแล้วปรับ Tune ได้
และคำที่สะกิดใจผมมากที่สุดคือ RAG
RAG คืออะไร?
RAG = Retrieval-Augmented Generation
ฟังดูซับซ้อน แต่หลักการง่ายมาก:
User ถาม → ค้นหาข้อมูลที่เกี่ยวข้อง → ยัดเข้า Prompt → AI ตอบพูดง่ายๆ คือ แทนที่จะให้ AI จำทุกอย่าง → ให้ AI ค้นหาก่อนแล้วค่อยตอบ
เหมือนนักเรียนที่สอบแบบ Open Book ดีกว่าให้ท่องจำทุกอย่างครับ
ทำไม RAG ถึงสำคัญ?
LLM ทุกตัวมีปัญหาเดียวกันคือ Hallucination — พูดเรื่องที่ไม่มีจริงด้วยความมั่นใจ 100%
ลองถาม ChatGPT ว่า “ยอดขายของบริษัทเราเดือนนี้เท่าไหร่?” — มันตอบได้ แต่ตอบ ผิดแน่นอน เพราะมันไม่รู้ข้อมูลภายในของคุณ
RAG แก้ปัญหานี้โดยการ ดึงข้อมูลจริงมาให้ AI ก่อนตอบ
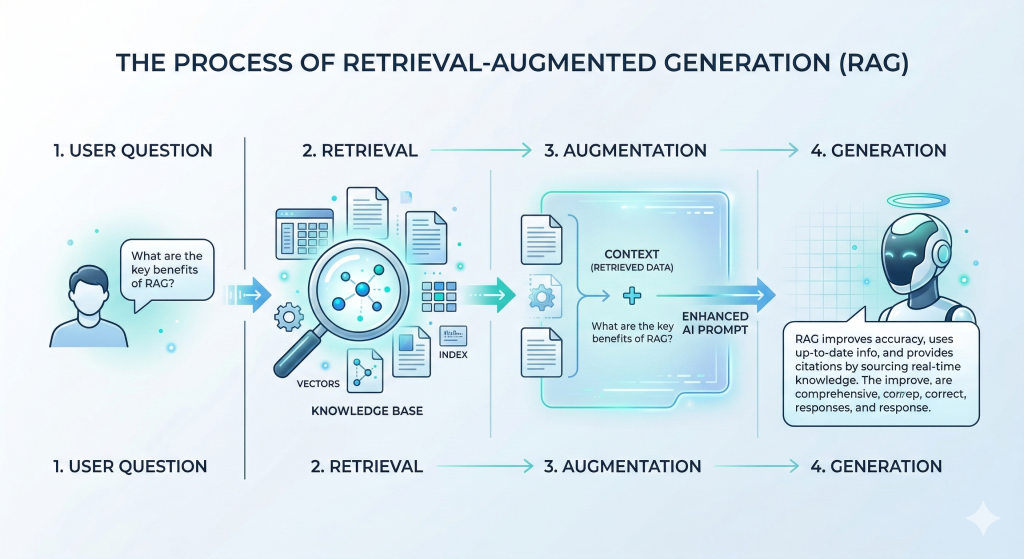
3 ขั้นตอนของ RAG
1. Retrieval — ค้นหา
นี่คือจุดที่คนส่วนใหญ่ทำแบบง่ายๆ แล้วหยุด แต่จริงๆ มีหลายวิธี:
Keyword Search (SQL/BM25)
User: "ยอดขาย Product A เดือนมกราคม"
→ SELECT * WHERE product = 'A' AND month = 'Jan'เร็ว แต่ต้องพิมพ์ถูกเป๊ะ ถ้าพิมพ์ผิดนิดเดียวก็ไม่เจอ
Vector Search (Semantic)
User: "สินค้าสำหรับเด็กแรกเกิด"
→ [0.2, 0.8, 0.1, ...] ← แปลงเป็น Vector
→ หาข้อมูลที่ "ความหมายใกล้เคียง"
→ เจอ: ทาล์ค, แป้ง, ครีมทาผิวเด็กฉลาดกว่า แต่บางทีก็ดึงข้อมูลที่ไม่ตรงมาด้วย
Hybrid Search (Vector + SQL)
Vector หาความหมาย + SQL กรองข้อมูลแน่นอน
→ ได้ทั้ง Semantic และ Exact matchนี่คือวิธีที่ production-grade ใช้กันจริงครับ
1.5 Reranking — คัดกรองผลลัพธ์
นี่คือขั้นตอนที่คนมักข้ามไป แต่สำคัญมากครับ
ดึงมาได้ 20 ชิ้น ไม่ได้แปลว่าทุกชิ้นเกี่ยวข้อง Reranker จะให้คะแนนแต่ละชิ้นแล้วเลือกเฉพาะที่ดีที่สุด:
❌ ไม่มี Reranker:
ดึงมา 20 ชิ้น → ยัดทั้งหมดเข้า Prompt
→ Context เต็มไปด้วยขยะ → คำตอบแย่
✅ มี Reranker:
ดึงมา 20 ชิ้น → คัดเหลือ Top-3 ที่ตรงที่สุด
→ Prompt สะอาด → คำตอบดีFlow ที่ถูกต้องจึงเป็น:
Retrieval → Reranking → Augmented → Generation
ดึง คัดกรอง เสริมข้อมูล ตอบ2. Augmented — เสริมข้อมูล
หลังจากดึงข้อมูลได้แล้ว ต้องยัดเข้า Prompt ให้ถูกวิธี:
❌ แบบง่าย: "นี่คือข้อมูล: [ยัดทุกอย่างเข้าไป] ตอบคำถาม"
✅ แบบดี:
- เลือกเฉพาะข้อมูลที่เกี่ยวข้อง (Top-K)
- ระบุ Source ชัดเจน (ข้อมูลจาก Report ไหน?)
- บอก AI ว่าข้อมูลนี้ใช้ได้ถึงวันที่เท่าไหร่
- สั่งให้ AI ห้ามแต่งเรื่องถ้าไม่มีข้อมูลContext Window มีขนาดจำกัด ยัดขยะเข้าไปมากเท่าไหร่ คำตอบก็แย่ลงเท่านั้น
3. Generation — สร้างคำตอบ
ขั้นตอนนี้คือส่วนที่คนเห็นมากที่สุด แต่จริงๆ ถ้า Retrieval และ Augmented ดี Generation ก็จะดีตามครับ
สิ่งที่ต้องระวัง:
- Source Citation — ให้ AI อ้างอิงแหล่งข้อมูลเสมอ
- Guardrails — ถ้าไม่มีข้อมูล ต้องบอกว่าไม่รู้ ไม่ใช่แต่งเอง
- Structured Output — บังคับ JSON format เพื่อ Validate ก่อนแสดงผล
สิ่งที่ตลาดหาจริงๆ
กลับมาที่บทความ HR ที่ผมอ่าน เขาบอกว่าคนที่หายากไม่ใช่คนที่ต่อ API OpenAI เป็น แต่คือคนที่:
- รู้ว่าจะ Retrieve ยังไง — Raw text / JSON / Vector / Hybrid
- รู้ว่าจะส่ง Context ยังไง — Single view / Multiple view / Window context
- รู้ว่าจะ Tune Prompt ยังไง — ให้ตอบตรง มีอ้างอิง ไม่แต่งเรื่อง
- วัดผลได้ — มี Evaluation pipeline บอกได้ว่าดีขึ้นหรือแย่ลง
ประสบการณ์จริงจากการสร้าง Production RAG
ในระบบที่ผมสร้างอยู่ เราใช้ RAG หลายชั้น:
- Structured RAG — ดึงข้อมูลผ่าน Tool Calling
- Hybrid Search — Vector (Upstash) + SQL (Azure) ทำงานร่วมกัน
- LangSmith — ติดตาม trace ทุก request พร้อม PII masking
- Guardrails — AI ห้ามตอบถ้าไม่มีข้อมูลจริง
สิ่งที่เรียนรู้มากที่สุดคือ RAG ไม่ใช่แค่ “ค้นแล้วส่ง” แต่คือการออกแบบทั้งระบบว่าข้อมูลจะไหลจากต้นทางไปถึง AI ได้อย่างถูกต้องและน่าเชื่อถือ
สรุป
Plug API ได้ → Junior
RAG เป็น → Mid
Tune RAG ได้ → Senior
วัดผล RAG ได้ → คนที่ตลาดหาAI Chatbot ทำง่ายจริงครับ แต่ Chatbot ที่ เชื่อถือได้ นั้นไม่ง่ายเลย
และความแตกต่างระหว่างสองอย่างนี้คือ RAG ที่ออกแบบมาดีนั่นเอง 🎯